In this post we will review few Data architecture patterns that started evolving during the big data era till recently, and their uses.
A historical timeline of these patterns and a few surrounding events as follows to set the context.
2004 - Apache Hadoop created. Hadoop distributed file system and MapReduce become the foundation of big data processing.
2008 - Apache Cassandra developed as distributed database to handle large amounts of data across commodity servers.
2011 - Lambda Data architecture introduced by Nathan Marz.
2012 - Apache Kafka developed, providing a distributed event streaming platform.
2014 - Jay Kreps, one of the co-founders of Apache Kafka, proposed the Kappa Architecture.
2016 - Apache Flink was developed, providing framework and distributed processing engine for stateful computations over unbounded and bounded data streams.
2019 - Databricks introduced Delta lake, an open-source storage layer that brings ACID transactions to Apache Spark and big data workloads.
2021 - Delta lake architectures mature, and widely adopted for simplifying data engineering needs.
Lambda architecture is a good starting point to trace this evolution.
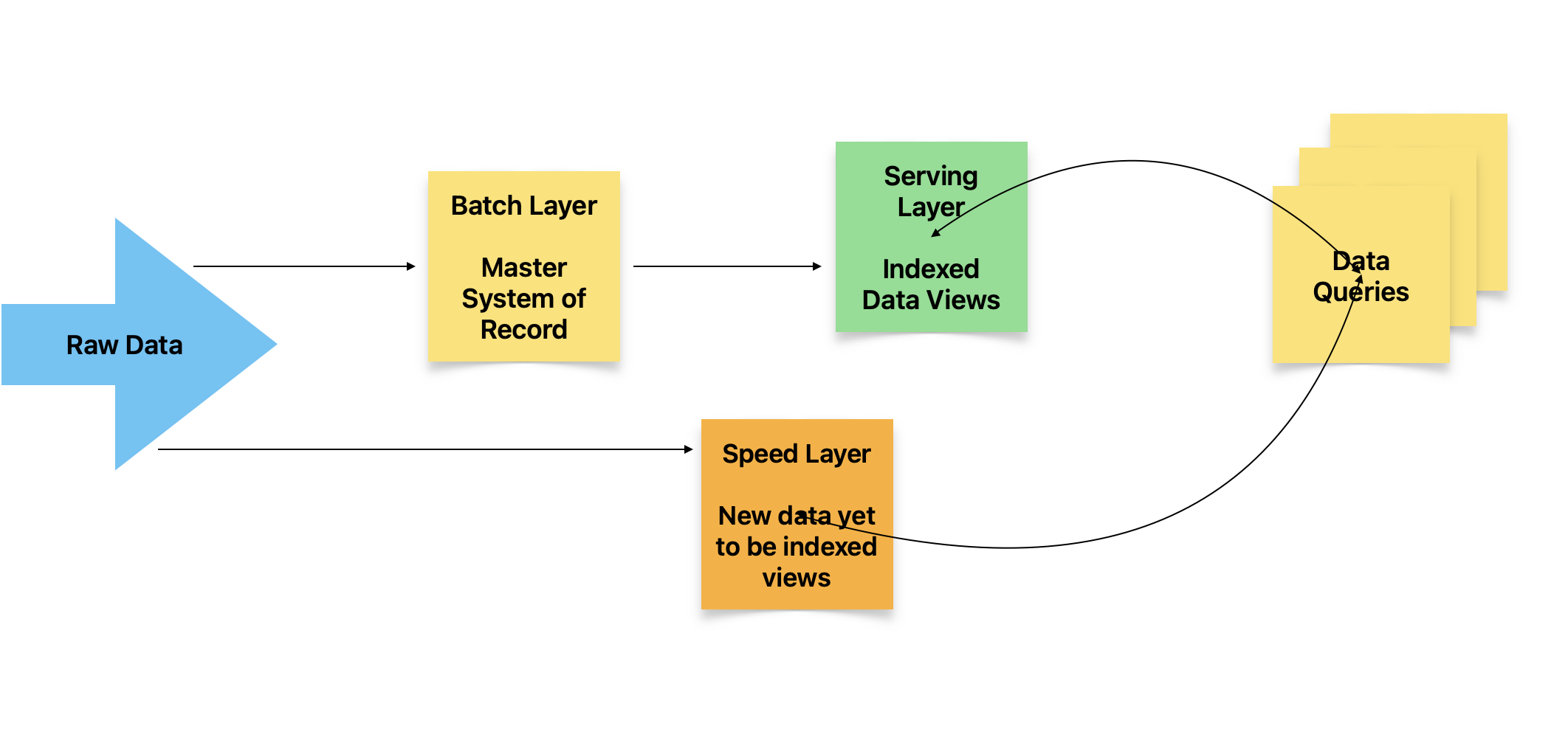
Fig 1: Lambda architecture
In this pattern we have provision for dealing with both batch processing and stream processing, in an elegant manner. As we can see from fig 1, batch and stream pipelines are kept separate. This separation is good as it is more efficient to process real time only when you have to, else it is better to tolerate the latency and do it in batch mode. When doing in batch mode you can even pick up schedules when shared server utilization is low, thereby avoid spinning up additional servers when their utilization is high.
The batch layer in Lambda will have a set batch size and a cutoff time. This data will be first appended without any modifications in the master system of record -immutable appends of any changes. So we don’t update or delete the original row, instead add an extra entry indicating its update with a time stamp. This way the master data stores the unfiltered source of truth of all transactions. Next, there is a serving layer that will create views or aggregations of most commonly used data access patterns by queries. So, this way the queries can benefit from a pre-computation, which can significantly reduce latencies.
The stream data will always have the last 1-2 hours window of data only. So if the query needs something recent in this window then it will get the answer from the streaming layer versus the views of serving layer above.
This pattern evolved in context of big data, however it can also be used with small data. It is also simple to implement in the latter scenarios without needing specialized frameworks. However it does have some limitations. In case of medium to big data scenarios you will need separate batch and streaming ETL pipelines. So now code is split into 2 parts for serving and may get difficult to maintain. Architecture will always have tradeoffs, so we just need to evaluate if a given set of tradeoffs will be fine for your team context. The plus in this pattern is that it is so intiutive as to how the pieces work, so one can debug issues at runtime in a transparent manner. I also like the fact that concerns of batch and streaming are separate and can be separately optimized based on the dynamics of each type of processing.
The next pattern is called Kappa. This came after Lambda and proposed to do away with the batch layer, and instead do all processing in a single stream layer built largely on top of Kafka. So this is very advantageous if real time processing of data such as those coming from IoT sensors and time sensitive alerts are the primary part of the application. It also simplifies maintenance by localizing the code in one streaming framework. However, this also has a limitation. Streaming data frameworks use queues to store incoming messages and then process. This will work for limited data size, however if there is large data needing pre-processing then the queues will not be able to handle the load. Besides, not all queries need low latency stream response - which can be unnecessary over-engineering.
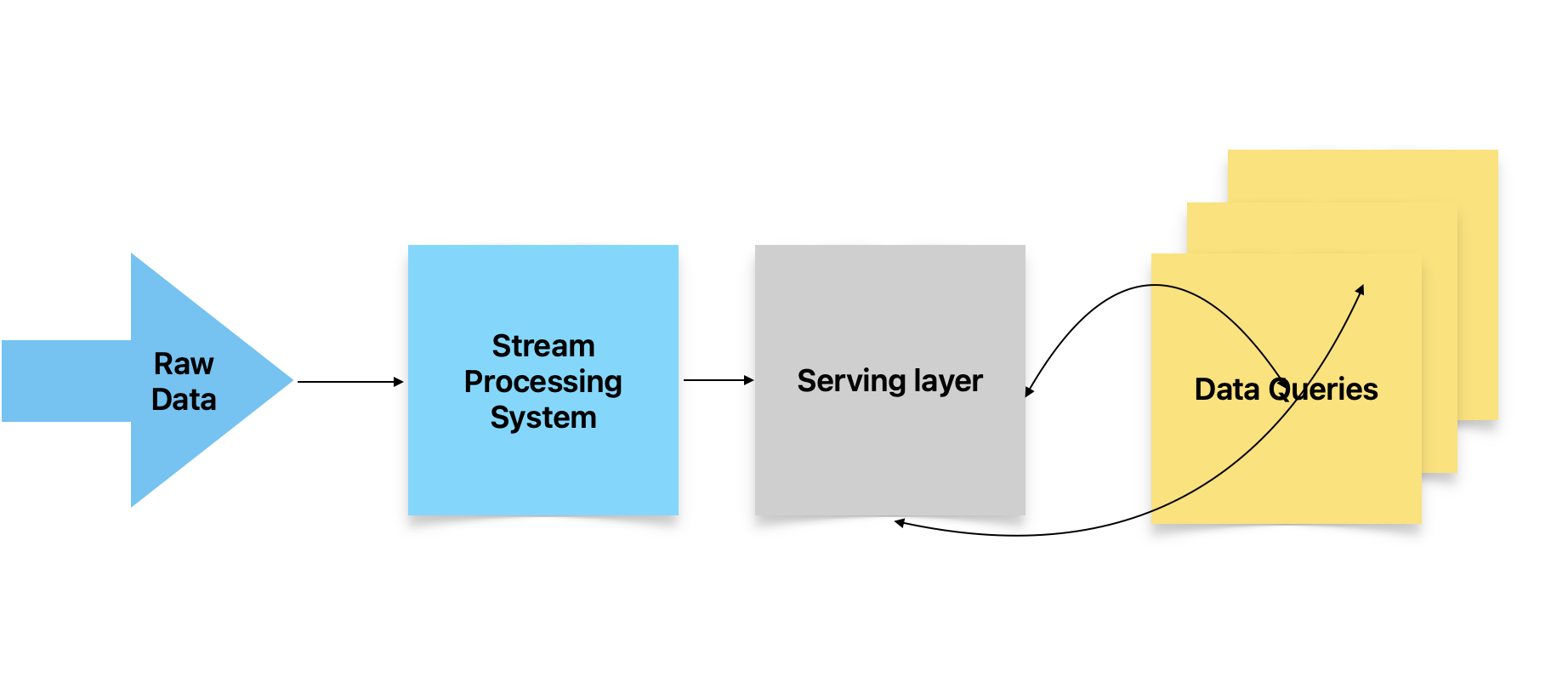
Fig 2: Kappa architecture
The latest pattern which aims to overcomes limitation of Lambda and Kappa is the Delta architecture. This brings to table an unified platform for both batching and streaming. It achieves this by leveraging micro-batching techniques- and is also the basis of modern Lakehouse architectures. Delta architecture simplifies by unifying batch and streaming data’s ingestion, processing, storing, and management in same pipeline by using a continuous data flow model.

Fig 3: Delta architecture
Source of this image: Databricks
As we can see from this diagram, there is a bronze, silver, and gold layer- corresponding to ingested, refined, and ready to use data. Delta lake is built on top of Parquet files with transaction log and ACID (Atomicity, Consistency, Isolation, Durability) transaction abilities, enabling robust and reliable data management. It also leverages Apache Spark compute power with the Delta lake storage management for achieving unified analytics capabilities. Platform providers such as Databricks and Snowflake provide managed services of this Delta architecture for easy consumption by development teams. This simplification for the end user is achieved by heavy lifting by Apache framwork and managed services providers.
While this is elegant for big data, it may still be an overkill for small data pipelines that need to deal with batch and streaming flows. For these small data scenarios Lambda can be easily adapted by developers, even without any heavy framework dependencies. In big data scenarios one can use Delta architectures and still control when batch jobs run. So you could use a combination of data filtering and scheduling for certain batch data, while the rest of the data can be continuously processed in micro-batches via the unified delta architectures. This way developer can get best of both the worlds - simplified unified processing and differential treatment of certain batch loads that can be scheduled when optimal to do so. One additional point is the testing of latencies in unified platforms, as batch and stream are combined. Although modern frameworks like Spark optimize the unification, there could still be some impact on streaming latency based on the workload dynamics.
In conclusion I will say that Lambda, Kappa, and Delta are all relevant and timeless architectures, each with their strengths and limitations - based on the specific requirements of your use case. Look at the nature of your data, requirements of data processing tasks, and resources available to you- and then decide the architecture pieces to deliver the exact solution needed by your customers.