In the world of data integration, various terms like ETL, ELT, Reverse ETL etc. are frequently mentioned, representing different architectural patterns.
To gain a clear understanding of these patterns, let’s start with defining the term.
ETL, an abbreviation for Extract, Transform, Load, encompasses a series of steps involved in the data integration process. The first step, “Extract,” involves retrieving raw data from diverse sources. These sources can range from databases, files, streaming sensor data, APIs, to enterprise systems. When dealing with databases, extraction often entails using SQL queries for relational databases, specific query languages for NoSQL databases like MongoDB or Cassandra, or even APIs for cloud-based databases.
Files come in various formats such as JSON, Excel, XML, CSV, Parquet, Avro, or plain text. The extraction phase typically incorporates logic to parse these files and extract relevant data. Similarly, REST APIs and web services transmit data in JSON or XML formats.
Streaming data, on the other hand, originates from sources like message queues, IoT gateways, or event streams.
Enterprise systems such as Salesforce CRM or Oracle ERP generally provide connectors to facilitate the extraction process. Additionally, in many machine learning applications involving text, web scraping—an approach that involves crawling and extracting text from multiple websites—is frequently employed.
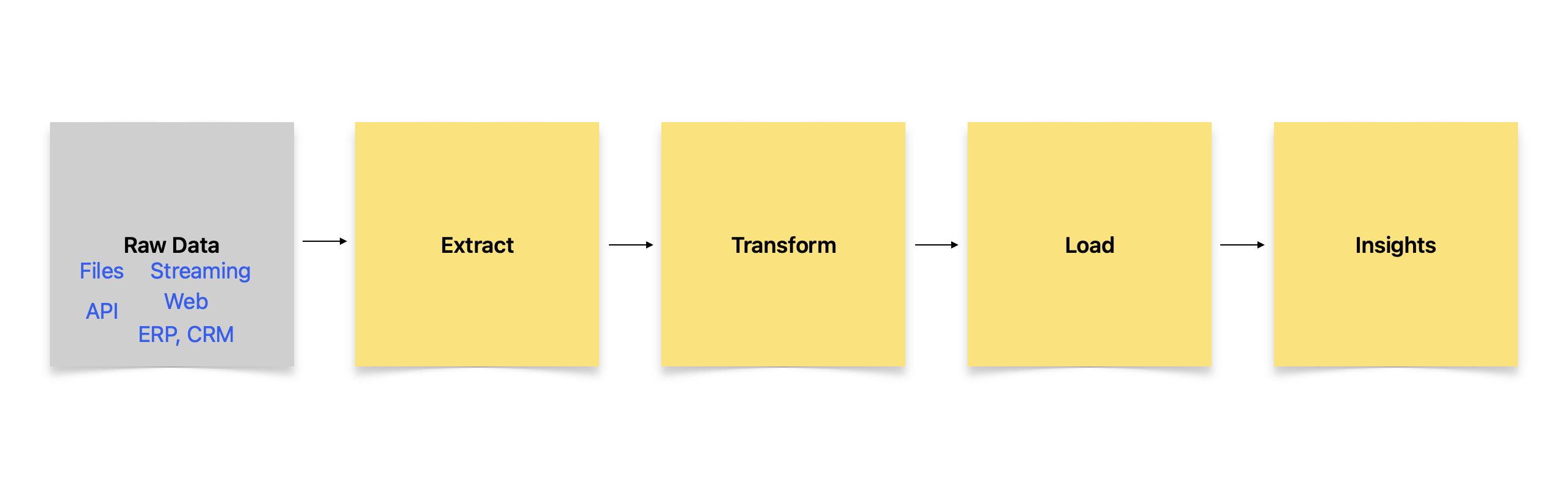
Parallel processing is also commonly used to extract data using distributed workloads for faster performance.
In traditional ETL the “Transform” step comes next, after extraction. This pattern emerged in an era when storage costs were expensive. In 2005 the disk storage was $406 per TB, $45 per TB in 2010 and in 2022 around $14 per TB. So it made sense for the ETL pattern to transform the data by various techniques even before loading it into target systems.
Of course one could argue that while the cost per TB of data storage has gone down, yet the volume of data has increased exponentially, so total storage cost is still gone much higher. Data has grown from 2 zettabytes in 2010 to over 100 zettabytes in 2022.
Data cleaning is a key part of transformation. This involves data quality checks, handing inconsistent values, missing entries and duplicates. Next up would be to reconcile between different formats and schemas of similar data obtained from disparate sources and fuse them together. Aggregation and filtering of data can also happen in this stage. For example, many small chirps of repeating data from IoT devices may be combined into an average or some repeating redundant data may be dropped. Likewise, data engineers may also enrich the extracted data at this stage by joining it with other external datasets or adding geolocation metadata etc.
Outlier detection and ensuring that data falls in the ranges that are appropriate for the business use case is also done in the Transform stage.
The transform processing is done using custom languages like Python, SQL, and ETL-specific software and tools provided by cloud platforms.
The last phase of ETL is the “Load” phase. Data that has been transformed in previous step is now ready to be loaded into the target system based on a defined data model. Target system can be Data warehouse, relational database, cloud-based storage or any system that has capacity to store and manage all this data.
In case the target system is a Database then the tables, columns, and relationships to hold the transformed data are defined, usually to make it suitable for further reporting in the pipeline.
Data can then be loaded using either batch, incremental, or realtime mode. Batch mode may use bulk inserts or target database import tools to load data in batches. In incremental loading, there is ETL process that runs and regularly updates only the delta changes. In realtime loading the data is captured as soon as data is available, given that these are likely use cases where the data loses value with elapsed time.
Load phase typically is never seamless and often there will be errors and issues. These would be captured in logs and the process checkpointed.
Once the data is loaded into target systems then the relevant indexes and other target system optimizations are done to ensure query performance. These may even kick off additional processes such as refreshing of materialized views in the target system, partitioning of large tables etc.
Now the stage is set for deriving insights from the data after ETL cycle.
Reverse ETL, as the name suggests is used to reverse the flow of ETL data from target system back into source systems. Purpose of reverse ETL is to push the enriched and loaded data back to source systems or operational systems where it can be leveraged for realtime actions. For example, a traditional ETL flow may have obtained customer data from a source CRM system. Later this data may be analyzed in the target system using machine learning to detect customer preferences, behaviors, and segmentation. This insight on getting pushed back to the CRM can now be used to do personalization for the customer, predict churn, and decide the next best action in customer interaction in the source system. Thus, we see that reverse ETL does not replace ETL but it complements it as part of the extended data stack.
Reverse ETL is harder than ETL. This is because reading from APIs is much easier than writing to APIs. Reading from multiple source system APIs require minimal or no authentication and authorization compared to writing operations. Reverse ETL may have the task of writing back to dozens of source system APIs and each may be very different from the other. Whereas ETL’s job was to read from these dozens of source systems and transform with only one target system for writes. Data validation and error handling is also a bigger concern when writing through an API end-point than reading from it. The other complication with reverse ETL is the lack of UPSERT operation that most data warehouses and DBs support in ETL. Whereas in reverse ETL the source systems typically won’t support this via API end-points. So, you need to keep explicit track of what is updated versus what is newly created. ETL jobs are also designed to be idempotent, meaning they produce the same results even if you run them multiple times. The target systems support this in ETL. However, in reverse ETL the source systems often won’t support idempotency. So one needs to be more careful in this case.
Next we come to ELT. ELT has become popular due to the rise of the modern cloud data warehouses that are very efficient in ingesting and loading raw data , and then transform only when it is required. So raw data is extracted and loaded first into these storages and transformation happens only when it’s required. So the target systems contain both raw and transformed data, and skips the need of a staging server used in traditional ETL.
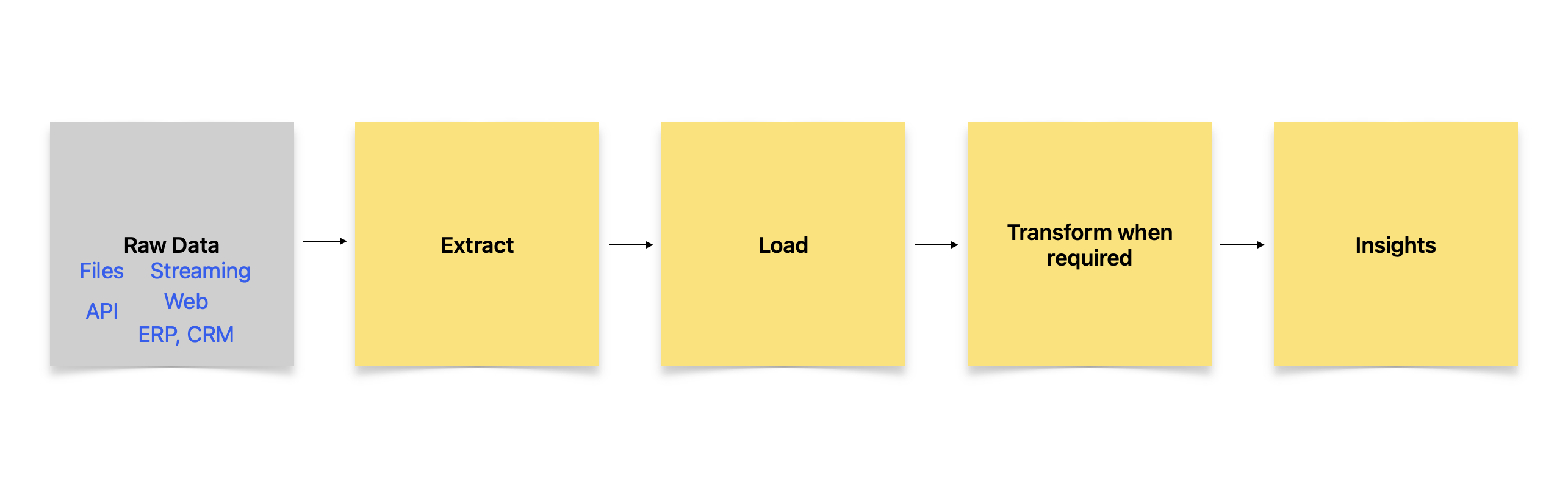
As an architect you may want to consider several aspects when deciding between ETL and ELT. If there is lot of PII (Personally identifiable information) in raw data then ETL is better as it can anonymize the data before loading into data warehouses. In ELT the raw data with PII may be accessible prior to transformation and this can be a security risk. ELT also may end up storing lot of unwanted data as no preprocessing happens before data movement. And data warehouse costs could go up really fast. On the other hand, if your use case needs rapid ingestion in real time and you have addressed the PII at source then ELT may have an upper hand over ETL. There could also be data that may have value at future date if stored in its raw state, which an ETL would have otherwise transformed prior. Also the lazy evaluation of only transforming what you need gives some efficiencies at cost of paying for all that extra raw data.
Two hypothetical examples follow below where the choices will be made between these approaches.
Let’s say you are a Telecom company that wants to analyze customer behaviour to improve the future marketing strategy. You have already invested in ETL tooling and real time insights is not required. Batch processing at defined intervals is required to adapt marketing strategy. Besides customer data privacy and security regulations are very important. In this scenario, it will be better to go with the ETL pattern.
In another example, let’s say you are a Smart city project that needs to analyze IoT sensor data to detect suspicious activity in certain areas in your city. In this case real time ingestion and analysis of data is very critical. Cloud based big data platforms are usually part of such a smart city architecture as this data is not coming within firewalls of an enterprise. PII is not really required at early data gathering stage, rather activity streams and patterns of humans in these monitored areas would be gathered. Such a project may also in future make use of social media streams and external newsfeeds. So ELT with a data lake architecture will be a good pattern to consider for this example.
A hybrid approach of ETL and ELT can also be good to consider in certain scenarios.
Let’s say you are a healthcare company that has structured Electronic Health Record (EHR) data from multiple sources. In addition, there is also unstructured data like x-ray images and scans that feed into machine learning algorithms for risk detection. ETL and ELT can both be used in such cases. ELT will be suitable for real time analysis for critical patient care decisions while batch processing in ETL is more suitable for analytics and reporting. ETL can also address health standards HIPAA requirements to ensure compliance for data anonymization and compliance, before loading into target systems. ELT on the other hand can help in accommodating integration and analysis of newer data sources using cloud based big data approaches.
So hybrid can be a good solution, where the architect can combine the strengths of both ETL and ELT selectively on subsets of their data engineering pipelines. This can “selectively” do upfront transformation of certain data like PII and any basic data cleansing. Later, after loading it can do more advanced transformations only on a need basis, such as data fusion and integration of multiple sources.
In conclusion, there is no one right answer for all scenarios. ETL, ELT, Reverse ETL, or a combination of all these techniques may be required depending on the nature of data processing and future data roadmap.
Credits:
Statistics on storage costs Our world in Data.