Data engineering today looks very different from the way it looked 5-7 years ago. This is due to certain technology factors- emergence of modern extraction-load-transformation (ELT) tools and the Cloud Data warehouses which provide decoupled storage and compute scalability in same platform.
In contrast, the traditional warehouses had coupled storage and compute, which lacked the flexibility of scaling them each independently.
In addition, there is a third factor - emergence of frameworks like dbt, Dataform, Matillion, and Apache Airflow that are bringing the Software Engineering rigour in Data Engineering. So modeling of data, version controlled transformations, reuse, and data lineage are now making the life of Data engineers lot easier than before.
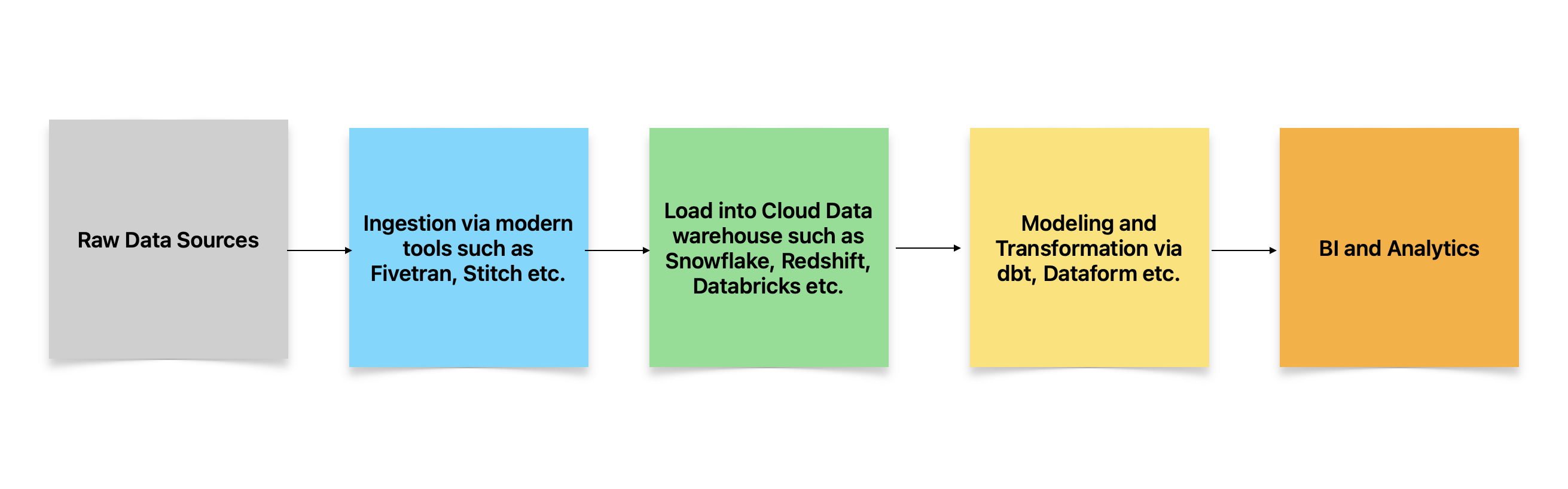
So this is how a modern data pipeline looks.
In a previous post on ETL vs ELT I had explained the differences between these approaches and motivated a middle ground where some transformation actually happens before loading the data. This is now called by many as ETLT and indeed the above modern data pipelines do employ this approach.
The first step is always extraction of raw data from various sources including operational data stores, web sites, custom documents, and APIs of external systems. Modern data ingestion tools like Fivetran and Stitch makes it really easy to do this extraction by means of connectors to various popular systems. Rewind few years ago, we would be writing custom code to do the same. The modern tools give ready to use reusable connectors and also migrate the schemas of the data into warehouse.
Before loading data into the warehouse there is typically a light “Transformation” , also called normalization such as data type correction or column name standardization or even duplicate reconciliation from multiple sources. This is the first “T” in the ETLT flow.
Modern ingestion tools also take care of automatically detecting schema changes in source and then reflecting it back to the destination warehouse. Compare this to the traditional approach of the past where we would write error-prone ingestion code and manually update when things change.
The ingested and normalized data is then stored in a cloud data warehouse such as Snowflake or Databricks, which use columnar storage and MPP (Massive Parallel Processing) for fast reads required by downstream analytical applications. The cloud data warehouses typically use proprietary columnar formats and few also use open formats like Parquet. Some of the OLTP data may be duplicated, however this is a tradeoff in return for the benefits of the warehouse.
Frameworks like dbt work on top of the warehouse like Snowflake- data transformation and modeling happens here. You can write SQL based transformation to clean, aggregate, and reshape data for analysis. For example, an e-commerce company may want to compute average order value (AOV) or customer lifetime value (CLV). The modeling may join customer data with transaction data to get a view of customer behavior and then calculate CLV based on total revenue per customer, order values, purchase frequency etc. It allows you to create and organize your transformations as reusable models, representing a table or view of your data in the destination warehouse. Relationships and dependencies between models can be captured in using what is called as ‘ref’ functions in the framework. This gives the execution order and the DAG (Directed Acyclic Graph) of data flows for the pipeline, including data flow and update lineages. These frameworks also use templating languages such as Jinja to write modular and reusable SQL code by defining variables, macros, conditional statements to generate dynamic SQL and enhance reuse of frequently used utility functions such as say date range filters or string manipulations.
Lastly, BI tools such as Looker or Tableau run on top of the transformed data in the warehouse to generate analytic dashboard capturing KPIs and important organizational metrics. Increasingly there is a trend towards self-service citizen BI tools, so the Business teams can generate their insights without depending on the Data experts.
Using these modern tools can save time, effort, developer experience, and at the same time scale while bringing in the discipline of software engineering to Data engineers. As an Architect you should still decide how much of transformation happens in the first “T” and then in the final “T” of the ETLT flow. Plus estimate the ingestion, storage, and compute costs of the modern tools and cloud data warehouse.