Large Language Models (LLMs) are a type of Generative AI that are trained on massive corpus of text data using cutting-edge Deep learning techniques to comprehend, predict, summarize, and generate new text based on user input. These models are often referred to as foundation models due to their vast size, featuring billions of parameters. GPT-3, GPT-4 are examples of this class of models. These are also called foundation models as they can serve as a basis for more specific use case scenarios with targeted refinements and optimizations.
Traditional NLP used techniques such as tokenization, stemming, lemmatization, part-of-speech tagging, and parsing to analyze natural language text data. Transformers evolved to solve the problem of long-range dependencies in sequences of text using mechanisms such as attention. LLMs leverage the Transformer architecture on the massive data that make them very powerful.
Traditionally, to enable functions such as text classification or sentiment analysis or question-answer function the developer would have built separate custom ML models. However with LLM, none of that is needed. It is a general purpose model built for a broad range of tasks and can be further given your app specific prompts or data to bring the context of your unique interactions.
“Prompt-engineering” is the discipline of specifying an action to be performed by a LLM. For example, you can ask a LLM model to write a poem in the personality of any poet- and they do a pretty good job. In prompt engineering you can also give further guardrails like number of lines, mood of the poem, total length etc., and these can be incorporated as input context to LLM.
Let’s look at this example below that I generated using OpenAI GPT model.
Prompt = "generate a poem on Data engineering. It should have 5 lines maximum. It should be funny. Use the persona of William Wordsworth to create this."
LLM response = "I wandered lonely as a cloud,
In a world of data, I was allowed.
Fields and tables, rows so fine,
But my query results, they did decline.
Oh, data engineering, you've tangled my mind!"
Apart from constraints such as above you can also feed in your specific domain document data to these models to enable querying the same.
LLM based applications are easy to prototype quickly, however not so easy to make production ready. Hence, many tools, startups, and frameworks are emerging to address the challenge of LLMOps. Langchain is an open source framework that is a great step in this direction, as it brings several utilities and advantages to building such applications. Langchain enables LLM apps to be data-aware and connect to other sources of data. It also allows LLM apps to interact with their environment using the concept of Agents.
Let’s consider a hypothetical use case where you have a bunch of custom documents in various sources that need to be queried for answers.
The data flow in Langchain app can be thought of as both ingestion flow and retrieval flows.
Ingestion flow looks as follows:

- Raw data is extracted from various sources such as intranet, documents, and databases.
- Langchain Document loaders are used to load data for use.
- Text may be split into chunks and then vector embeddings are created.
- Vector data is then stored in Vector DBs and indexed.
Retrieval flow looks as follows:
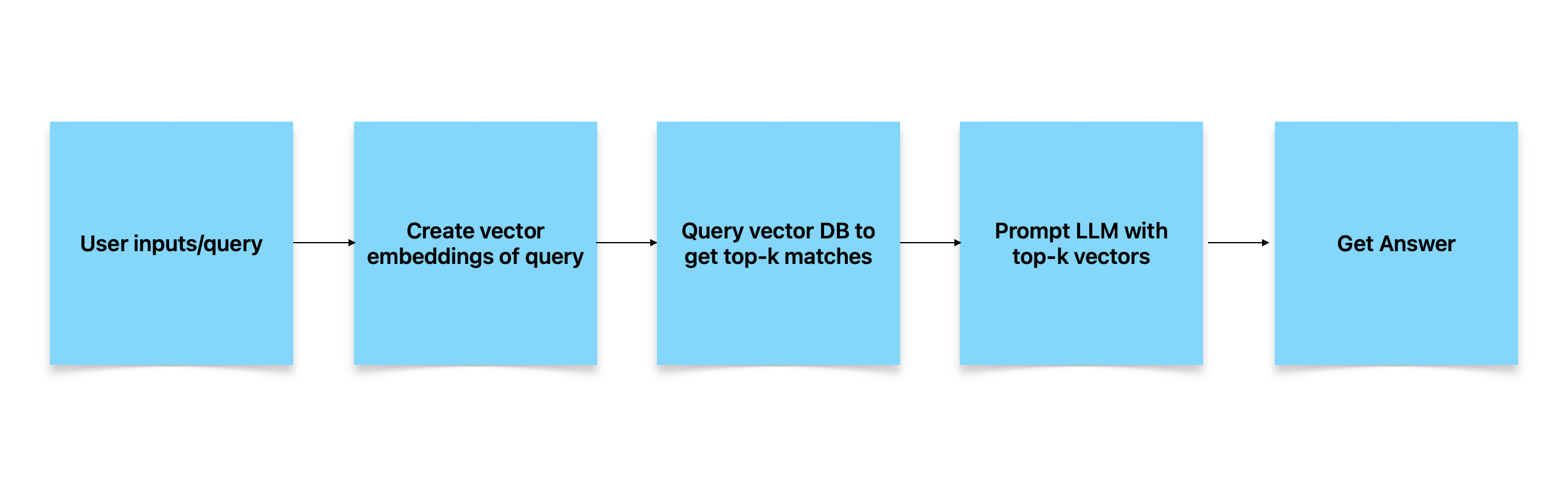
- User can input a prompt with context as query.
- Create vector embeddings of the query.
- Run the query against Vector DB store and fetch top-k matches.
- Prompt LLM model with the top-k vectors from above.
- Receive a generated answer from LLM.
Langchain allows the application code to work with closed or open source LLM models. It has abstractions that allow developer to change LLM model in code easily by using the built in parameter in its methods. Prompt templates also can be combined with input variables in Langchain to dynamically create prompt text. And these constructs enable easier reuse. You could also choose to store the vector embeddings either in memory vectors or in a vector store of choice such as Chroma, FAISS, Weaviate etc. It also gives you ability to store conversation history for longer context. LLM also has output parsers when you need output to be in say JSON or CSV and then programmatically access it or pass it on to other APIs. The most powerful feature of Langchain is its abillity to create pipelines by chaining together multiple components in an intiutive manner. Agents in Langchain can dynamically decide at run time on the course of action it has to take with available tools and data.
Interestingly, one of the use cases that is emerging is how to use LLMs for Data Engineering tasks such as SQL interactions, data transformations, and even report generations. In subsequent posts I will try to go into some of these examples.
For a detailed list of use cases and hand-on tutorials refer to Langchain.