Modern enterprise collaboration often relies on team chats and conversations between experts and team members. Video recordings of such events are the norm, but it is cumbersome to retrieve useful information from these files.
Now, with Langchain and LLMs, this problem can be elegantly solved.
Let’s dive in.
Conversation transcripts, whether entirely human or involving AI agents, can be fed into LLMs. These models’ NLP techniques can then be leveraged to extract entities, summarize lengthy discussions, and even generate semantic ontologies of the content—making it more suitable for human consumption.
In a previous post, I detailed how LLMs and semantic knowledge graphs have a strong synergy in terms of use cases. You can refer to the link for an architectural understanding of this concept. In this article, let’s explore Langchain further to demonstrate how some of these possibilities become a reality.
By default, any conversations powered by LLMs do not preserve state; they provide answers only in the context of the most recent question. However, Langchain APIs can be configured to save memory in multiple ways.
Memory here refers to the system’s ability to store past interactions, including context of user inputs for future use and querying.
Various memory utilities available are:
ConversationBuffer - A buffer of past chat history, subject to token length limits.
ConversationBufferWindow - similar to the above but limited to the last K interactions.
ConversationEntityMemory - remembers given facts about entities in chat.
ConversationKnowledgeGraph persists in the form of a knowledge graph to recreate memory or past context for future use.
ConversationSummary - summarizes the chat.
ConversationSummaryBufferMemory - a buffer of recent interactions with summaries of older flushed interactions, flushing based on token lengths.
ConversationTokenBufferMemory - uses token length for flushing.
VectorStoreRetrieverMemory - backed by VectorDB-based persistence and querying; this one does not track the order of interactions like most others above.
Each of the memory classes is suitable for certain types of use cases, as can be clearly understood from the descriptions above. Let’s illustrate this with examples of Entity, summary, and KG (Knowledge Graph) memories.
Shown below is a chat that will leverage entity detection.
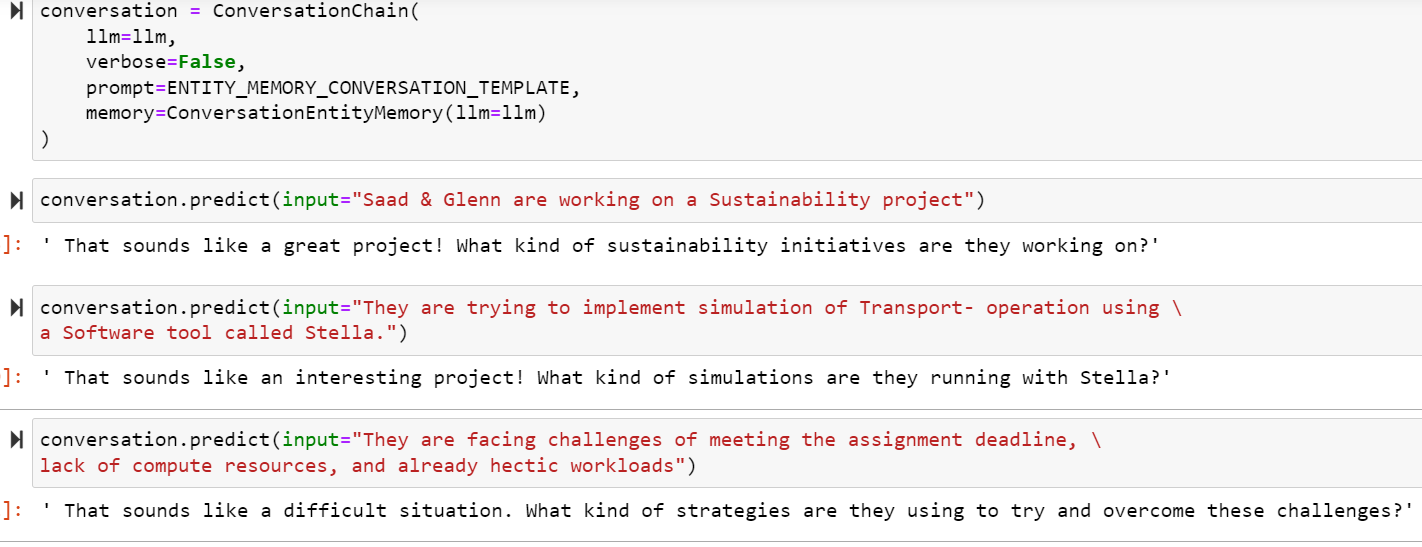
And when we print the output of the state, shows as follows:
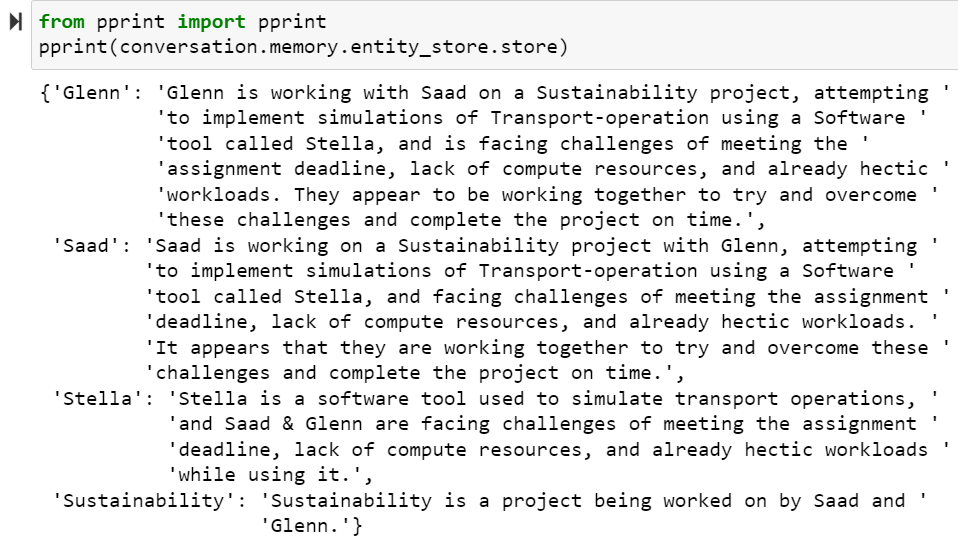
This is incredibly useful as most transcripts have lot of noise, and a reader may need to distill down to the core entities that comprise the dialogue.
The next scenario is a conversation from which we want to extract knowledge with semantic associations. The conversation is shown as below.
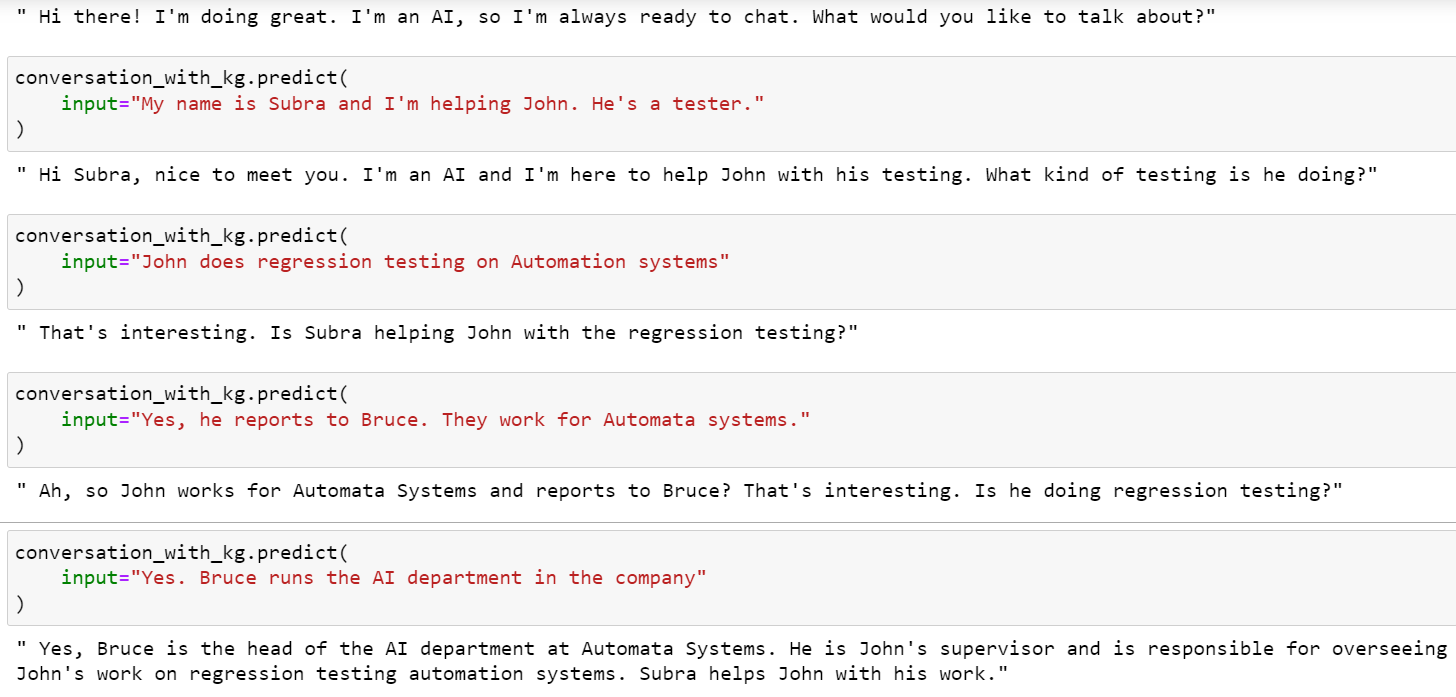
This code above generates knowledge graph triples, which upon feeding into a python function using Networkx genererates the below output:
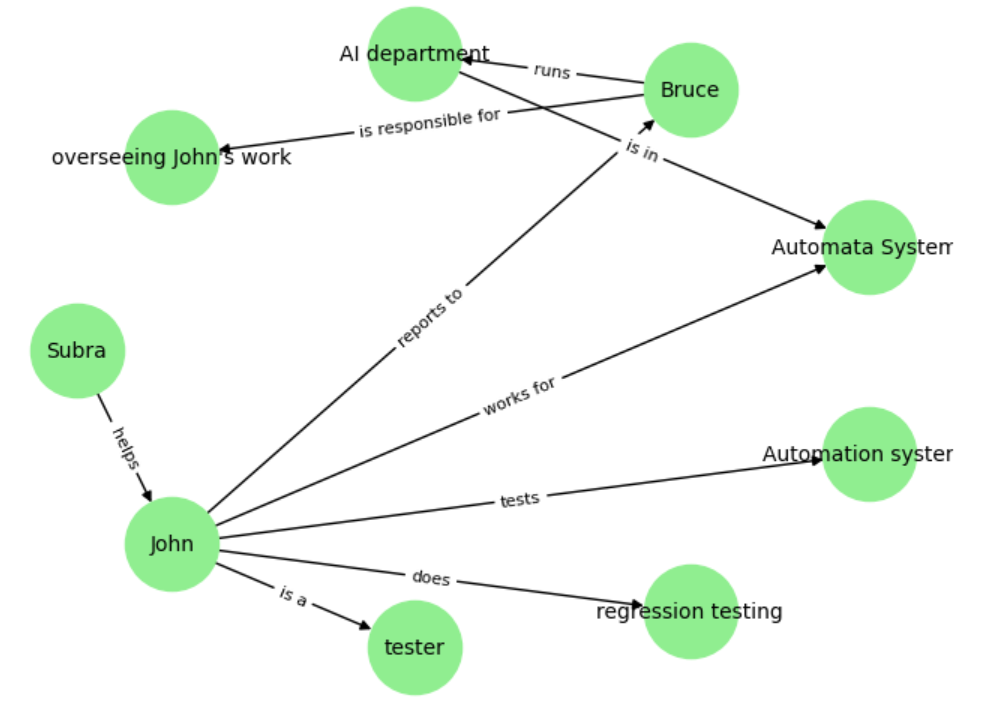
Incidentally I used GPT to generate the graph output visualization code!
In the final scenario I show how long conversations can be summarized using such utilities. See the chat and the resulting memory state that is distilled to its essence. This is very useful when we want extract the signal out of all the noise.
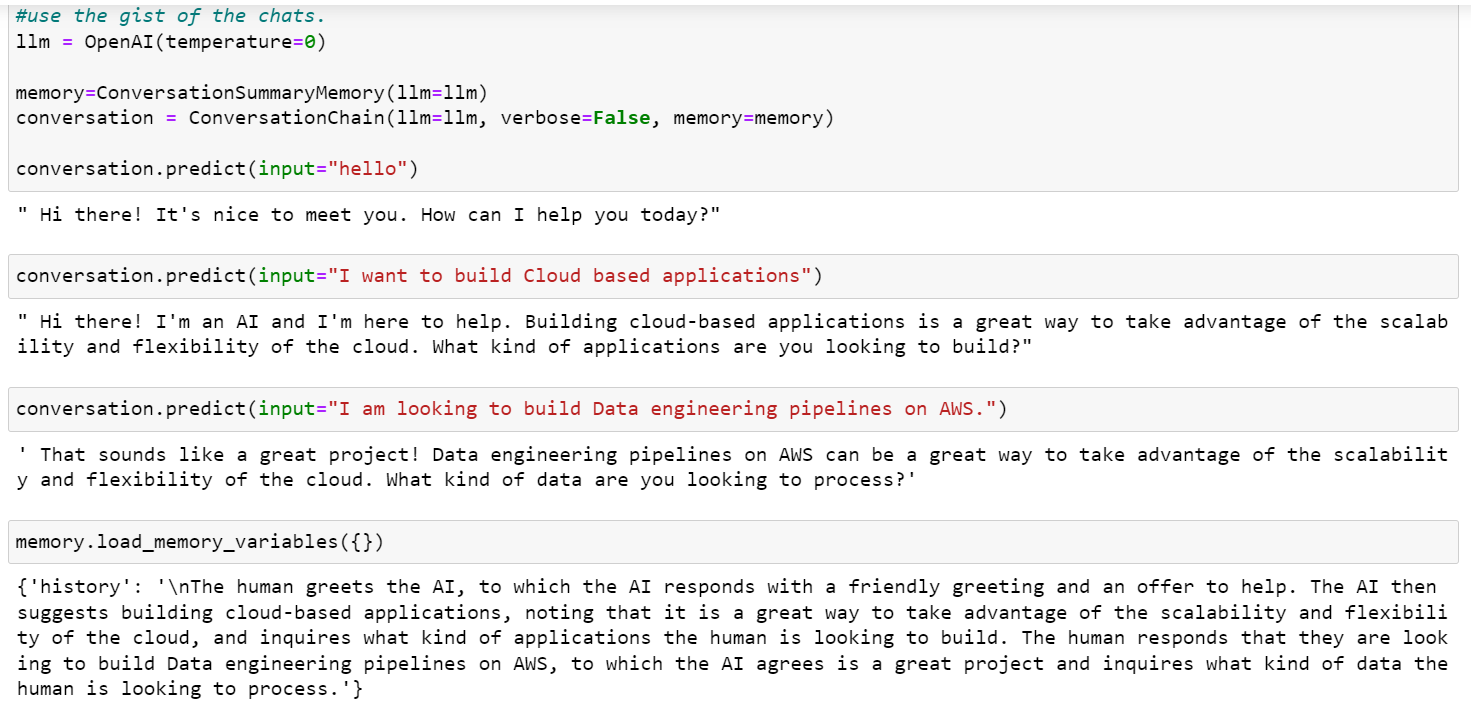
By choosing the right memory class and techniques, you can transform conversations into valuable knowledge assets for your enterprise.