In this post we will zoom into the concept of Serverless ETL and the role it plays in Data pipelines feeding MLOps. Along the way we will also expand on the implications for LLMOps in Generative AI scenarios.
First we start with definitions.
What is ETL?
In a previous post we have detailed the many flavors of ETL, ELT, and even ETLT. To recap, it is a fundamental starting step in Data ingestion part of any pipeline. Here is where the raw source data is extracted, transformed into better formats, and then moved to a target storage to make it ready for serving to scenarios such as Machine Learning.
What is Serverless? Let’s go via negativa here. Serverless does not mean there are no servers. It also does not mean there is reserved and pre-provisioned servers. Developers don’t have to deal with even configuration, management, maintainance, fault tolerance, or container scaling issues. Instead Serverless is an execution model on the cloud where the cloud provider such as AWS or Google provide instances of servers on demand - spin up for use and then spin back down when not needed.
Serverless + ETL: Combining Serverless and ETL can be a highly effective strategy under certain circumstances. To understand why, let’s begin by looking at it from a different perspective. It might not be the best choice if your ETL needs are continuous 24/7, as the constant starting and stopping of instances can lead to significant overhead. In such cases, opting for reserved instances may prove more cost-effective.
However, in most scenarios, ETL requirements follow a specific pattern. Initially, there’s an intense period of ETL activity at the outset of MLOps model development. After that, ETL tasks are typically batched based on factors like model drift or the need to recalibrate with new data distributions. In such situations, there’s no justification for keeping virtual machines or servers up and running idly when no processing is taking place. This approach would only consume valuable resources unnecessarily.
Tooling options
We can take the example of AWS Glue to illustrate the steps. Other cloud providers like Google and Microsoft Azure also have equivalent tooling.
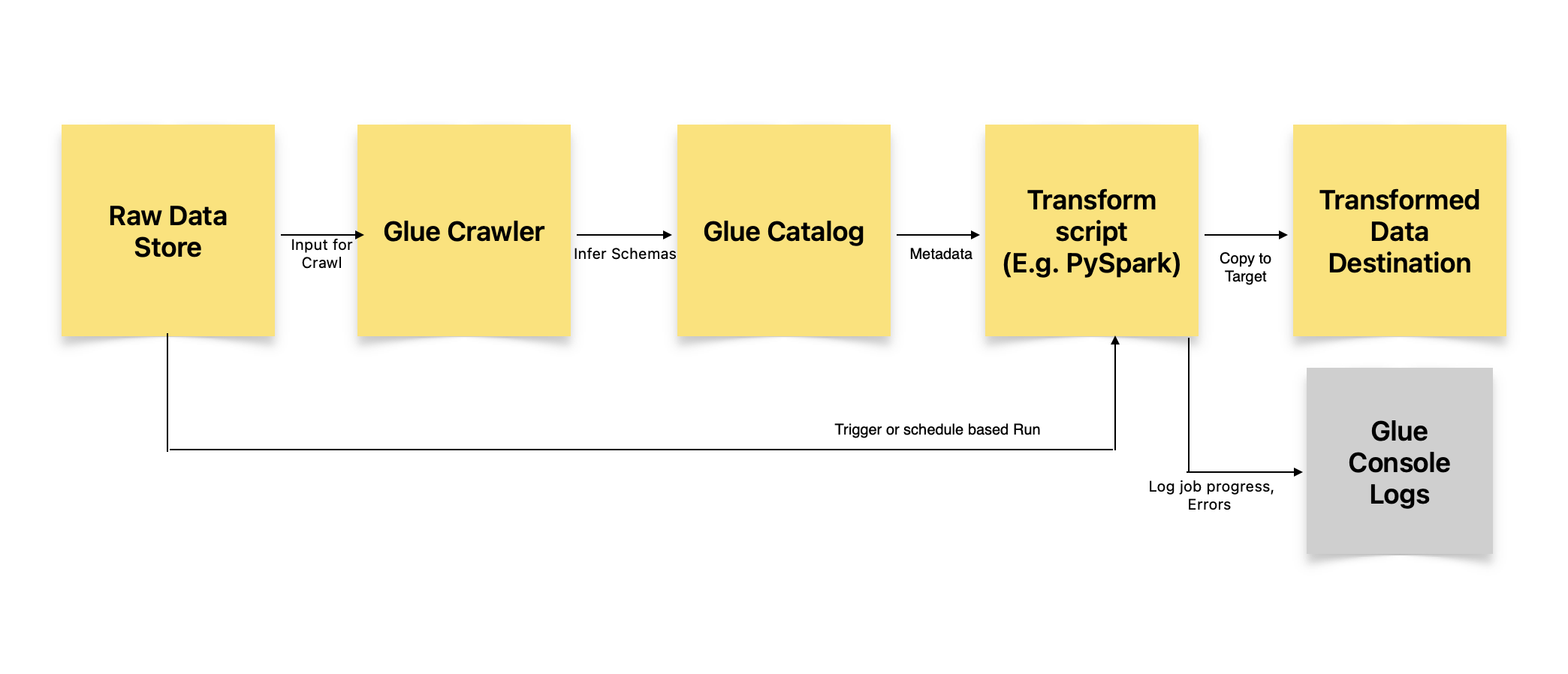
AWS Glue is a serverless ETL that can crawl the source data, extract metadata, and perform any transformation prior to loading into target datastore like S3.
Zooming into AWS Glue:
- Assume that source data files such as CSV are in your S3 bucket.
- You intend to transform this CSV into a format such as Apache Parquet that is optimized for analytical queries.
- You create a “crawler” in Glue. This crawls the source data, extracts metadata such as field names, types etc. and stores the meta information in Glue catalog.
- Next you can create a “glue job” to do transformation. Glue interface helps in generating the Python or Spark code for the same.
- For example, one could write a pyspark code to convert the CSV into Parquet and move it into a new destination bucket. In this step you could also specify the number of DPUs (Data Processing Units) to run. This allocates the computational resources allocated to your job. And pyspark is inherently capable of doing parallel processing on the underlying hardware.
Had you created a plain vanilla Python with Pandas library, then it would not be parallel jobs but instead be single-threaded. - AWS Glue also logs the job progress and results to console for later use.
How is AWS EMR Serverless different from Glue?
AWS EMR Serverless is tailored for large-scale big data processing. With this service, AWS takes care of managing map-reduce operations and provides a suite of tools like Hadoop, Presto, Pig, Hive, and Spark. This robust infrastructure is ideal for handling massive datasets and complex data processing tasks.
On the other hand, Glue offers a more straightforward and versatile solution that can accommodate both small and large datasets. It is user-friendly and doesn’t require deep expertise in big data technologies. It’s a versatile choice for a wide range of data processing needs.
It’s important to note that AWS EMR can be more complex, even when fully managed. It’s essentially an overkill for smaller datasets, and working with it demands a solid understanding of cluster computing and parallel processing patterns typical of big data platforms like Hadoop. This makes it more suitable for specialized use cases where extensive big data capabilities are required.
Additional ETL considerations for Large Language Models and Gen AI
Large language models rely on embeddings to convert text into numerical vectors, as explained in a previous post. Therefore, these applications require an “Embedding ETL” process to generate and continuously update these embeddings, aligning them with the evolving context. This process also involves synchronizing the destination Vector databases responsible for storing the vectorized transformations.
Managing this process can become complex when dealing with multiple corpora of data used to train or fine-tune large language models, which may contain duplicate chunks of text. Consequently, the chunking method employed must be capable of reconciling and de-duplicating these chunks, which may pose challenges for standard chunking approaches.
Moreover, the task of extracting data from various sources such as websites, books, audio, or video files and transforming it into contextually relevant chunks that fit within the context window of the large language model introduces additional complexities.
Lastly, in more intricate application scenarios, such as those involving ETL for Generative AI, it becomes imperative to implement a comprehensive quality assurance framework to ensure the robustness and reliability of the systems in place. This includes a series of rigorous checks to validate the integrity of data and the accuracy of transformations within the ETL pipeline.
As technology continues to advance, Serverless ETL will likely become more integral to data processing and decision making, in both MLOps and LLMOps scenarios.
Sources Referred:
AWS Glue Documentation
AWS EMR Documentation