Recently, Microsoft has made the SK (Semantic Kernel) SDK, a lightweight tool, available as open source on GitHub at link.
The term “semantic” here refers to the semantic completion and semantic similarity, two operations that are key in large language models.
Semantic completion is predicting the next words in applications like conversation.
Semantic similarity is finding similar subset of text based on given inputs.
Kernel is a reference to the Unix kernel philosophy. In Unix you could either use simple commands or even combine them as a pipeline using the “|” symbol that can take the output of one command and feed it as input to next command.
Similarly the semantic kernel also allows such composable software.
In addition to semantic functions it can also integrate native functions in application.
Semantic functions are good with text, however not so good in maths, where native functions perform better.
Native functions have annotations that will be the metadata used at orchestration time.
So apps would benefit from an ability to leverage mix of both semantic and native abilities.
Semantic functions can be created by specifying 2 components:
a. Prompt template : natural language query with parameter placeholders.
b. Configuration data: Settings for the semantic function such as temperature, token limits etc.
Configuration data can be passed as function parameters or as a JSON config file. File is preferred in more complex cases needing lot of parameter options.
Semantic Kernel is typically made of Plugins, Planner, and Persona.
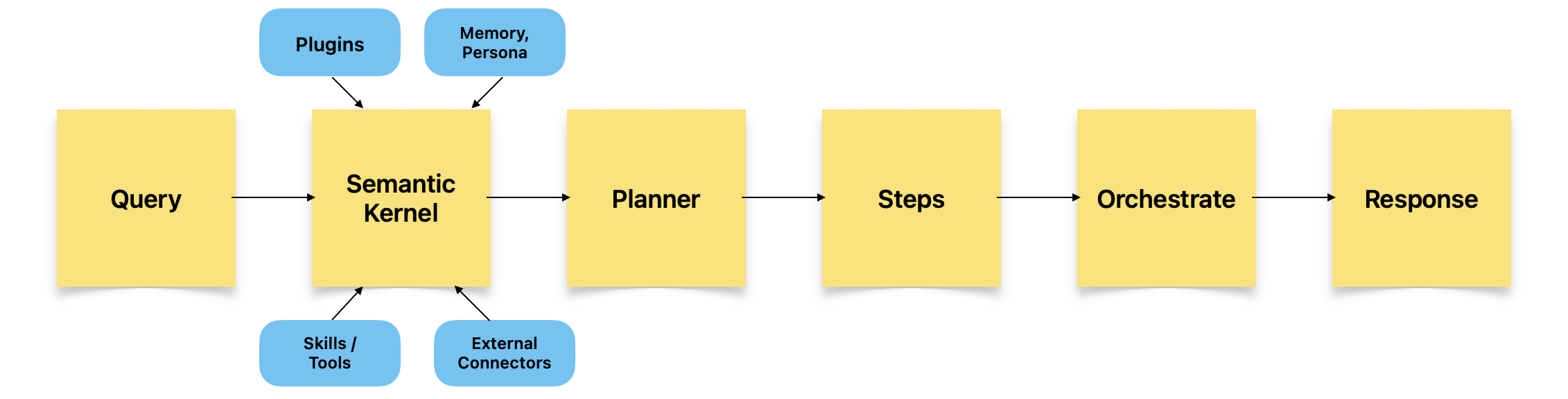
The prompts and configurations become plugins to the kernel. Likewise, skills such as those having context of maths, file IO, Http, Timeskill etc. are also added as plugins.
Plugin model enables more easy sharing across projects.
Planner uses the plugins to chain together complex flows to achieve a goal comprised of multiple tasks.
Context data such as text of conversations or input documents are converted into vector embeddings and stored in Vector databases, for use by the semantic functions.
These enable the concept of semantic similarity using techniques such as K-nearest neighbors. This enables a powerful ability called RAG (Retrieval augmented generation), where relevant context data can be retrieved and used to prompt the models for more accurate generation. So one can think of RAG sitting at the intersection of semantic similarity and semantic completion, aided by emdeddings.
And lastly, the persona - think of this like a profile that captures the preferences and personality of the Semantic kernel- further augmenting the context stored in short and long term memory and the RAG.
This is very similar to Langchain functionality which I covered in an earlier post, and I will draw parallels.
Kernel object is similar to the Chains in Langchain.
Planner is very similar to Langchain Agent.
Plugins are similar to Langchain tools.
And vector memory is same in both approaches.
Microsoft SK emphasizes the enterprise readiness of their SDK and advanced features such as async execution.
At the same time Langchain is also very comprehensive and rich in features including Async, plus some additional capabilities which may be yet to come in Microsoft SK.
In terms of popularity, feature richness, models supported, vector stores support, and types of agents Langchain seems to have a clear lead. The simplicity of use and elegance of using MSK is definitely appealing, and given that it will mature , it is something to lookout for as a strong alternative along with LangChain to craft the next generation Generative AI applications.