RAG (Retrieval-Augmented Generation) fills a very useful spot on the Gen AI spectrum.
What is it and why do we need it?
It is a way to refer to an external corpus of documents which has not been used to train the LLM. This is very important for various reasons, as follows.
Cutoff date: LLM model knowledge has cutoff date. Given that it must have taken months to train it, the upstream process may have referred to only data before the date that the training started.
Sensitive data: Your organization may have private data or domain specific information that you may not want to use in training a LLM, for safety reasons.
Dynamic data: Data that changes fast is also something that cannot be bottled inside a model.
Cost constraints: Even if you had stable data to re-train a LLM, you may not necessarily have the compute budget to do this, let alone the environmental cost of carbon emissions in the process.
How exactly does RAG work?
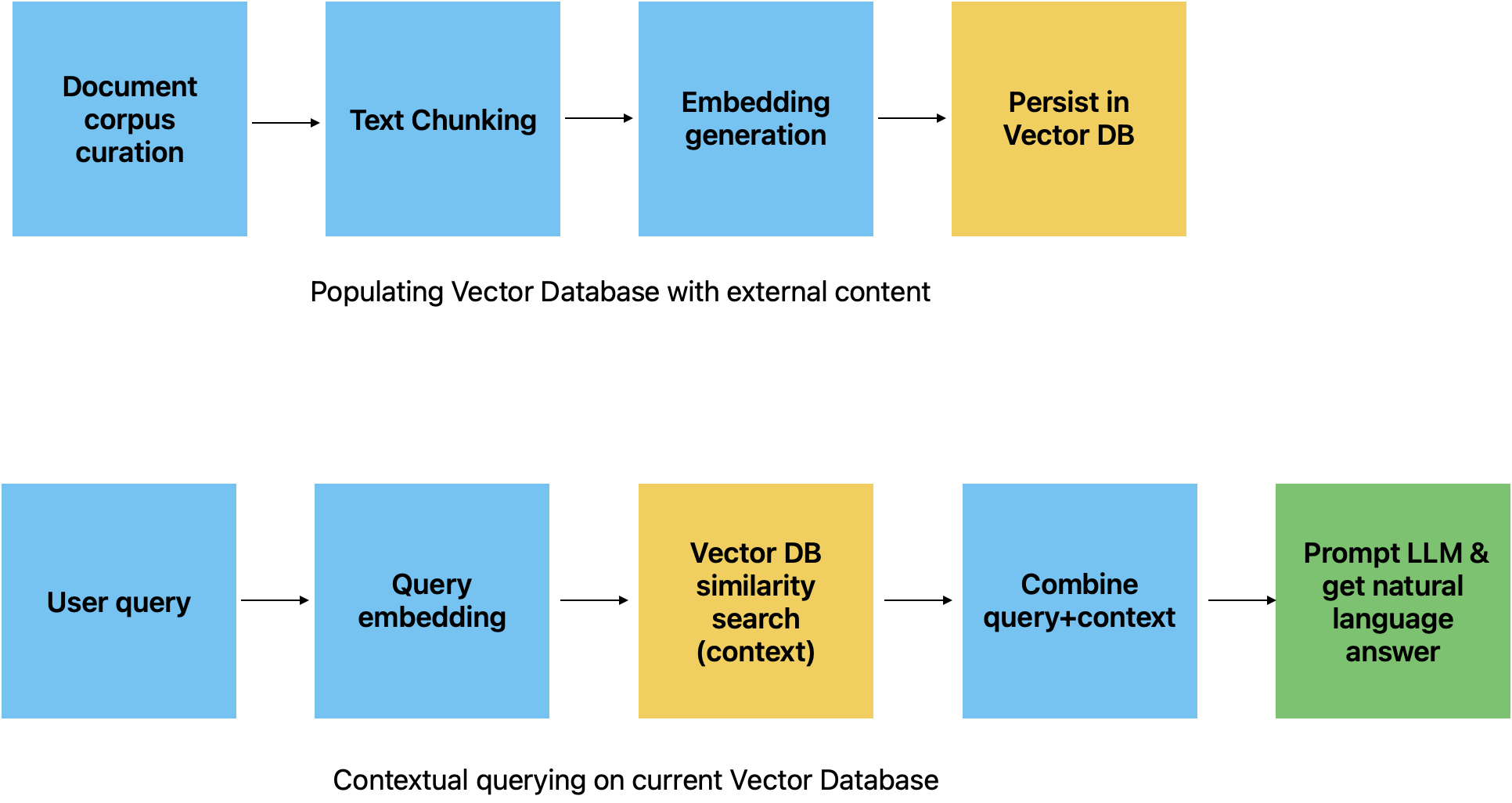
Document Preparation:
Convert a set of external documents (e.g., PDFs, text files, APIs) into numerical representations suitable for searching in an “n-dimensional” space.
Use an embeddings model to convert the text into embeddings. This process involves “chunking” the text into smaller segments before embedding them into vectors. Chunking ensures that only the most relevant parts of the document are retrieved, avoiding large, irrelevant sections.
Storage:
Store the encoded text (vectors) in a persistent storage solution. Specialized databases called
Vector DBs are purpose-built for handling this type of vector data.
Query Handling:
When a user issues a query, intercept it and convert it into a vector using an embedding model.
Use the vectorized query to search the vector database for document chunks similar to the user query.
Combining and Generating Response: Combine the user query with the retrieved context from the vector database. Send this combined prompt to the LLM, which will return more relevant answers by augmenting its knowledge with new and current external document parts relevant to the user.
Ideally, the embedding model used to encode the corpus should be different from the embedding model used to encode the user’s query. This approach leverages the strengths of different models specialized for encoding longer documents including domain-specific and shorter queries, respectively.
Summary:
Retrieval-Augmented Generation (RAG) is a powerful approach that extends the capabilities of large language models by integrating external, up-to-date, and domain-specific knowledge. By effectively combining the strengths of vector databases and LLMs, RAG enables more accurate and relevant responses without the need for costly retraining. As organizations continue to seek ways to leverage their proprietary data while maintaining efficiency and security, RAG stands out as a versatile and scalable solution.